1582
-
Posts
9 -
Joined
-
Last visited
-
This has been my dream for many years now.
-
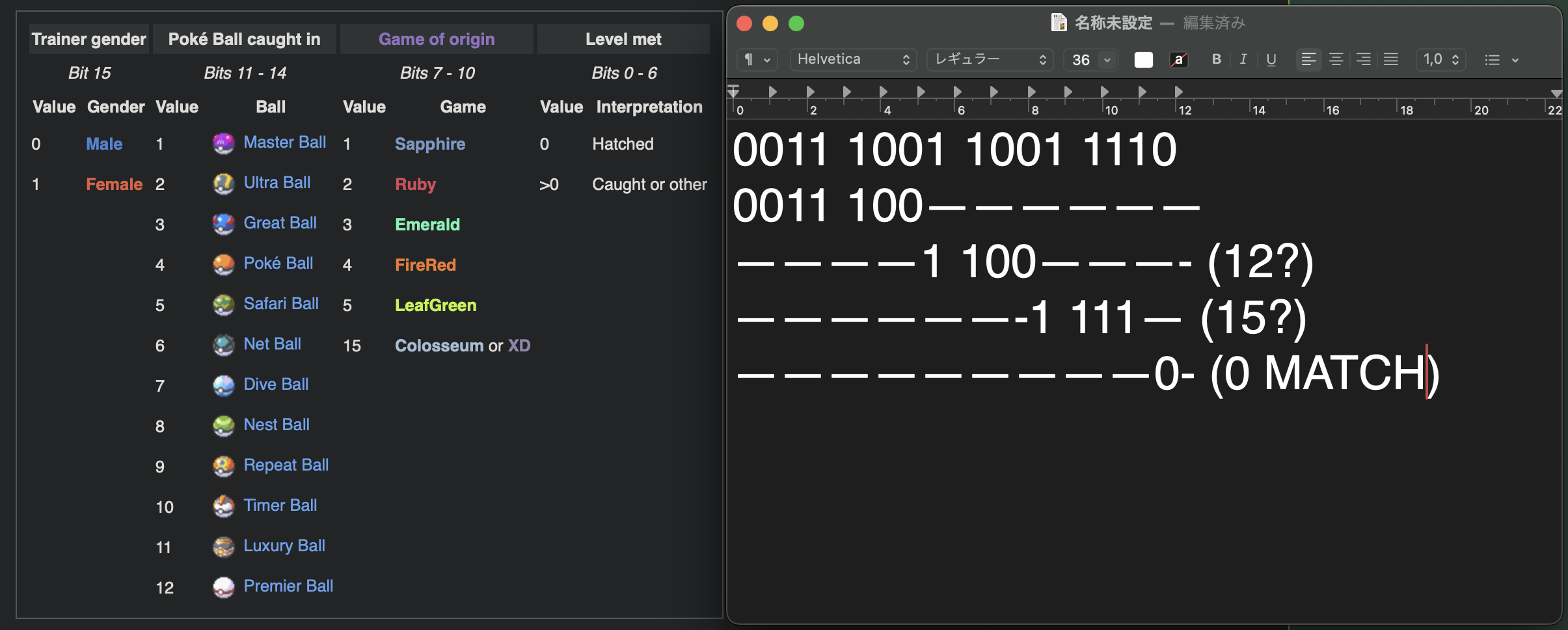
I suppose I understand, but I also keep realising how lucky I keep getting with this endeavour. First of all, I would have to learn and do so much more (which isn't inherently bad) if PKHeX hadn't saved all of my Pokemon in a decrypted and non-shuffled form. Also, this 16-bit sequence is consistent after the 7 times shift. I understand that normally I would've had to shift the bits each time for each of the pieces of info I was trying to get, but somehow by shifting it by 7 bits it has a consistent and accurate placement of all of the info, such as: trainer gender, pokeball used, game of origin. I was able to parse the species name and the nickname of the Pokemon in python today and am extremely happy, without your help it would've been impossible, so thanks for all the insight. As always, will probably bother again sometime.
-
Sorry for the late reply; I tried this and this does wonders, everything just sits in place so perfectly. May I ask why we shift the bits by 7 specifically? (I understand that that is the number that made it "make sense", so to speak, but is there more to the number? Also, This method is consistent with the bit placement, but what Bulbapedia had as indexes doesn't really work anymore. Thank you so much, though. Will probably bother again sometime, as annoying as it might be, all of this is just too interesting.
-
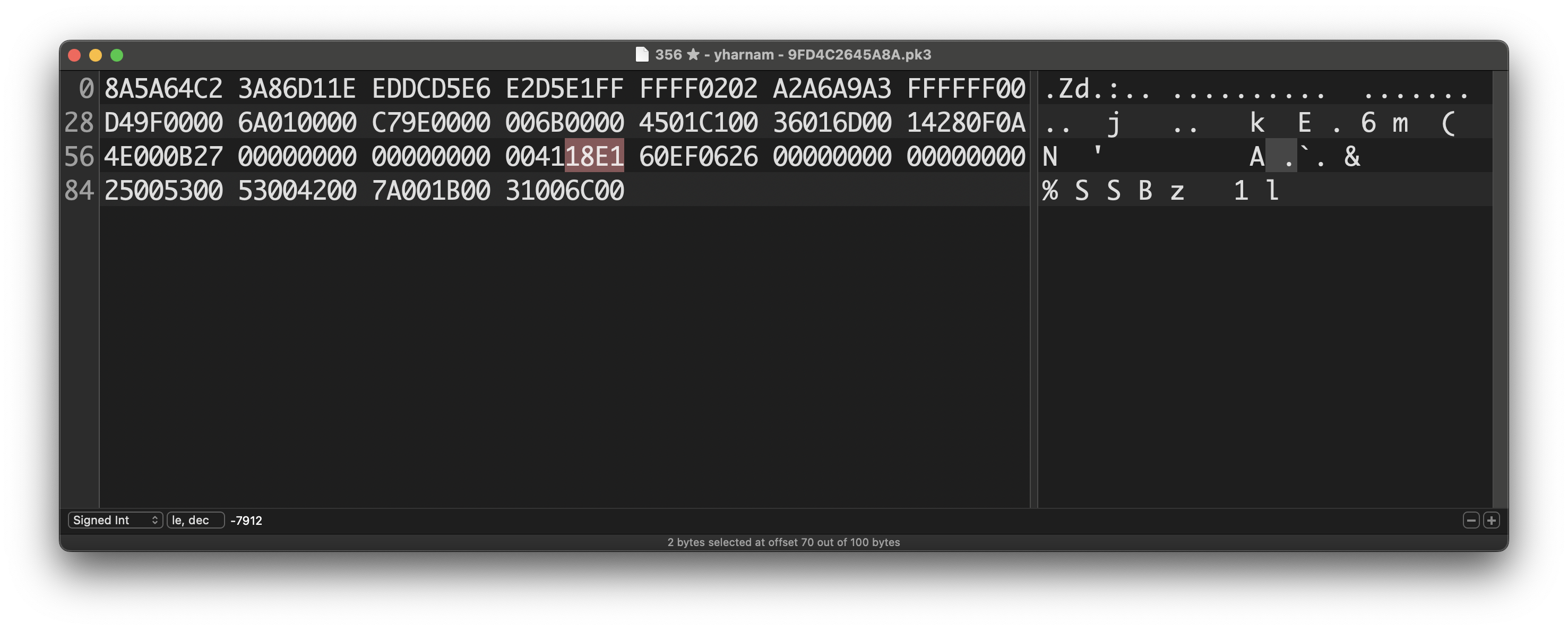
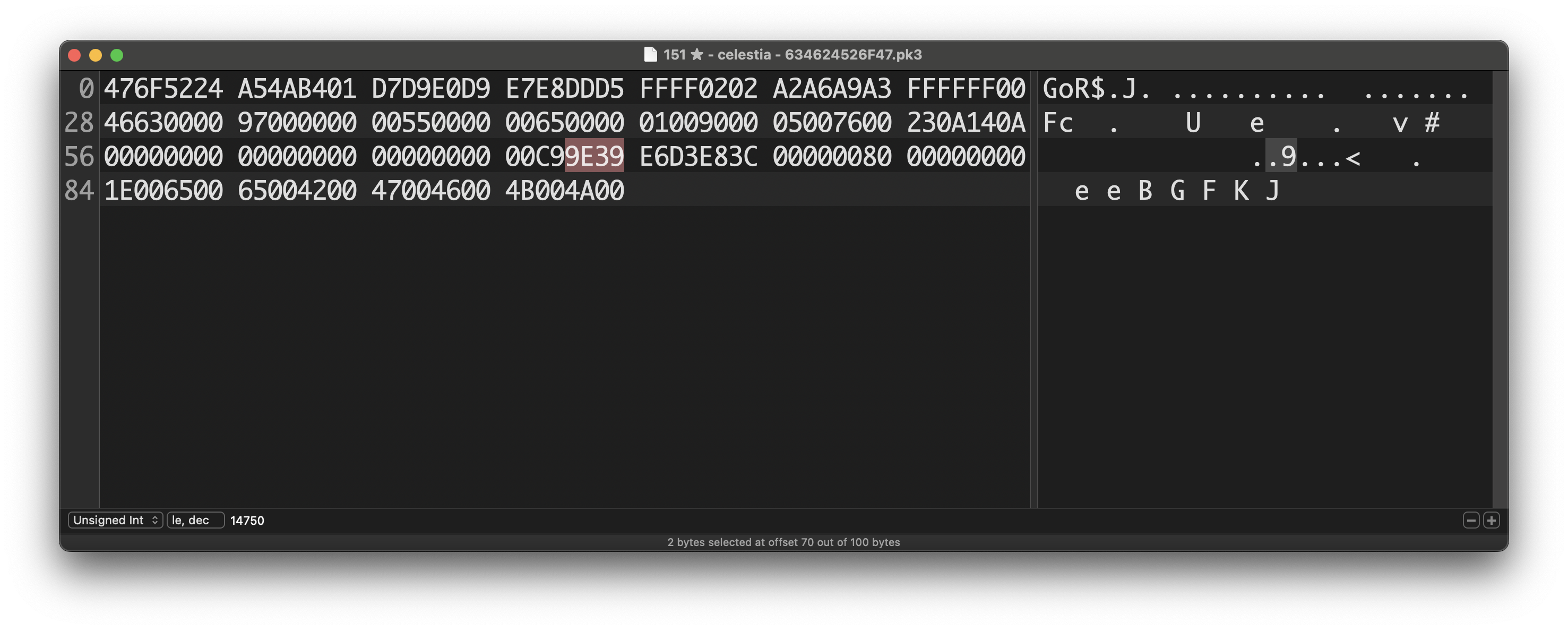
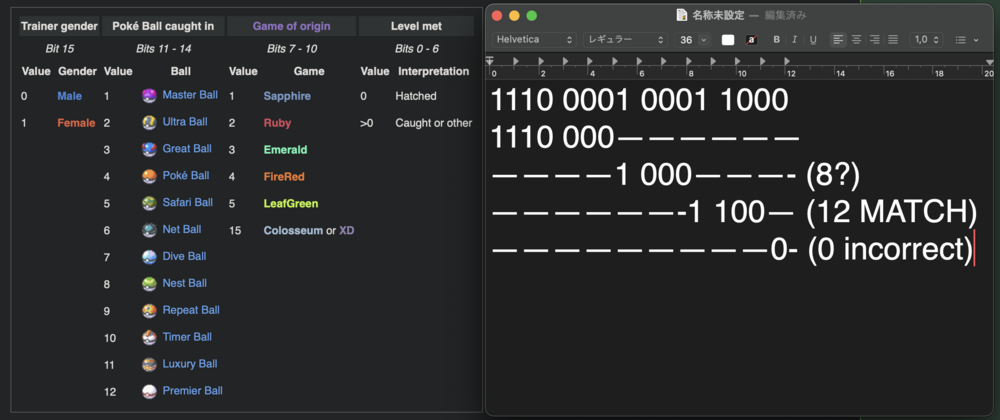
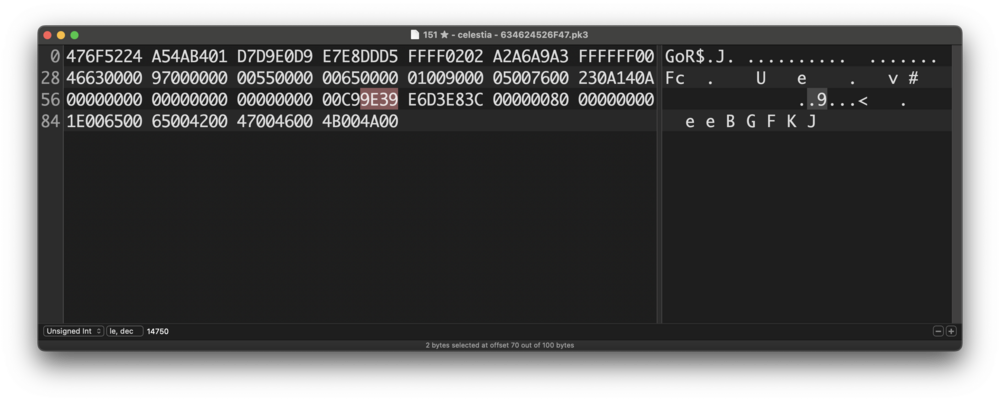
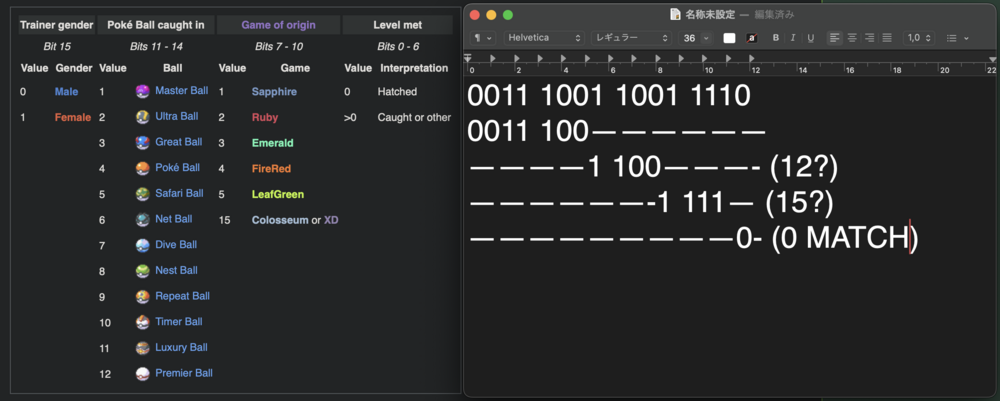
I considered the endianness and tried both ways (despite ChatGPT telling me it was not needed in translation to binary), but either way it didn't match. I understand all of this might be getting slightly annoying, but I just don't have any other better source, so please understand why I'm being pesky about this. Let me explain with an example: Here I have the hex for my Dusclops from Ruby Everything, including other info from the 48-byte Data structure lines up, until we reach the two highlighted bytes, that should be the Origins info. I tried both little-endian and big-endian conversions, but for the sake of this example (neither of the two matched anyway) I'll show the one you proposed. The game of origin doesn't only not match, but it's a random not even relevant. The pokeball did match actually, but my guess is it's just a coincidence, since I tried with another example and it no longer matched. The trainer gender doesn't match the in-game gender either. This is the part that is confusing to me. I'll show one more example with my Mew from Emerald; Here's the entire hex and, again everything matches, so the two highlighted hex become our point of focus. Here, both the game of origin and the pokeball are numbers that are completely off, but the trainer gender matches (that one should be an easy coincidence). All in all, I don't know what I'm doing wrong and the fact that everything else lines up and matches besides this very part, being the part most important to me, is what's making me ask so many times. I apologise for the sheer amount of questions, but I hope these examples provide a clearer image of what I can't figure out.
-
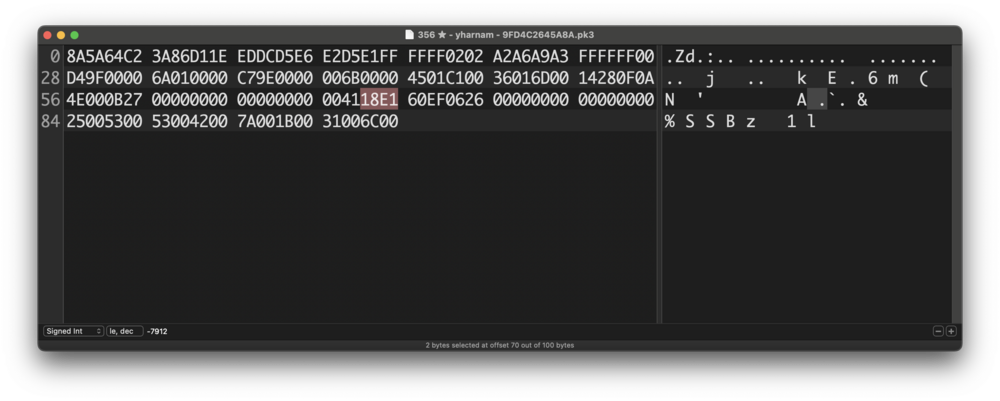
Yeah, I tried comparing the results I get to the in-game info and everything seems to line up besides the "Origins info". For my Dusclops, the Hex corresponding to that segment is 18 E1, and when I convert it to binary I get 0001 1000 1110 0001, which is the only piece of info I am struggling with to align with the in-game material. I'm following the same bit-by-bit principle as shown on bulbapedia, but the info just doesn't match. Is there another conversion method I'm missing?
-
So I started working with .pk3 files in a hex editor and grasped most of how it was organised, but one thing (and arguably the most important part), being the Data section at offset 0x20 is extremely confusing to me. It's confusing for 2 main reasons: 1) The G, A, E and M order should be scrambled, but from my own shiny pokemon files, I've noticed they've been consistently in GAEM order. Does PKHeX do this automatically (since that's how I extracted these files) ? Or, is the shininess somehow the reason for this consistency. 2) Everything seems to align with the GAEM table here, but the part I'm the most curious about, which is "Origins info" in the Miscellaneous section. I might be converting the hex to binary wrong, but the binary I get just doesn't make any sense in this context. Even the trainer gender is off. I'd appreciate any help, if it isn't of too much trouble, thanks.
-
Yeah, I understand the issue at hand more thanks to you. Super grateful for the insight and the help. Might come back with some questions as I progress through the project, but thanks a lot.
-
Thanks for the reply; Honestly, I only really need to parse the name of the species, the nickname, the types, the pokeball, the level and the game of origin (don't know how possible this last one is). I just need to read the bytes at the offsets and convert the corresponding numbers to data via an external source right? (f.e. the number at the offset for the pokeball is 3 an according to some source of pokeball codes, number 3 would be an ultra ball). Would Bulbapedia be a good source for that? My questions might be all over the place, so I apologise again for my lack of understanding.
-
Greetings, Super noob here when it comes to this kind of stuff, but for my CS50 final project I decided to create an offline .pkx bank-like app in python using tkinter, sort-of how PKHeX looks, but basically just for storage. For that, I need to parse the .pkx files to get some needed info for the mons displayed. I could just theoretically create a separate text file that stores all of this info from some other source and just look it up with the Pokemon national dex index that PKHeX automatically puts at the start of the file upon extraction, but I feel like that would be extremely inefficient. How exactly would one go from a .pkx file to something akin to a dictionary for practical use in python? This might be a question asked a hundred thousand times and I have very little technical knowledge, so any help would be appreciated. Thanks.